Security-First Deployments
RAG Implementation for Internal Knowledge and Production Workflows
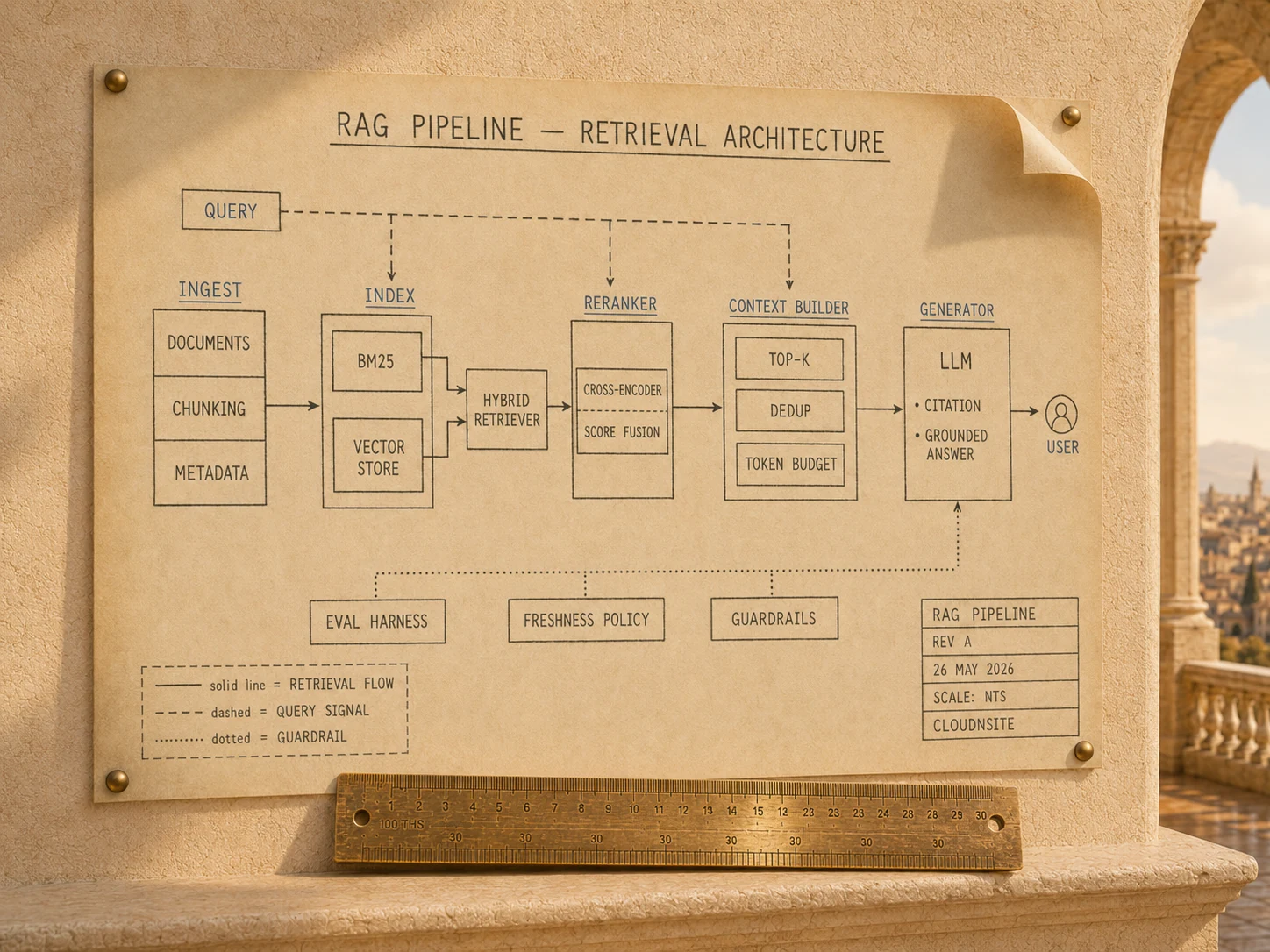
CloudNSite designs, builds, and operates retrieval-augmented generation (RAG) systems for internal knowledge, customer support, and agentic workflows. Hybrid search, reranking, source attribution, and an evaluation harness that catches hallucination and source drift before any production query. Live in 4 to 8 weeks with ongoing tuning and monitoring.
System diagram
Pain Points
ChatGPT keeps making things up about our docs
Generic LLM answers cite plausible but wrong sources, conflate similar policies, and miss the most recent update. Production RAG grounds every answer in retrieved passages with attribution and refuses when the evidence is weak.
Search across our knowledge bases is broken
Confluence, SharePoint, Google Drive, Notion, and the ticket archive each have their own search. The team gives up and pings a senior person. A RAG system unifies retrieval across sources with permissions intact.
Vector search alone is not enough
Pure embedding search misses exact-match queries (product SKUs, policy numbers, ticket IDs). Hybrid retrieval combining BM25 keyword and dense vector search with a reranker is the production minimum.
Stale answers persist after the source updates
A RAG system that does not track source freshness keeps citing last quarter's policy. Production RAG includes change detection, reindex pipelines, and version-aware retrieval.
Permissions get lost when documents become embeddings
Indexing everything into one shared vector store leaks sensitive content to users who should not see it. Production RAG enforces per-query permission checks against the source-of-truth ACL, not the index.
How Our Agents Solve This
Internal Knowledge Assistant
Answers employee questions about policies, procedures, product specs, and customer history with retrieval from Confluence, SharePoint, Google Drive, Notion, ticketing, and the data warehouse. Every answer includes source links.
Customer Support Copilot
Retrieves from the help center, product docs, known-issues database, and the ticket archive to draft accurate replies for support agents. Confidence scores route low-confidence drafts to senior review.
Sales Knowledge Agent
Pulls competitive intel, pricing rules, contract precedents, and customer history from CRM, CPQ, and shared drives to brief reps before calls and answer questions in the deal room.
Legal and Contract Retrieval
Indexes the contract archive with clause-level retrieval, surfaces precedent language, flags non-standard terms, and links every answer back to the source contract section.
Engineering Runbook Agent
Retrieves across runbooks, incident postmortems, code comments, and observability dashboards to answer operational questions during on-call rotations with source attribution.
Regulated-Industry RAG
HIPAA-ready or financial-services-ready RAG that enforces per-query authorization against the source ACL, redacts PII or PHI before it reaches the model, and logs every retrieval for audit.
Expected Results
How Implementation Works
- 1
Source mapping and ACL audit
Inventory the knowledge sources, document their access controls, identify the freshness signals (updated_at fields, change feeds, webhooks), and decide which sources are in scope for which user groups. Permissions design happens before indexing.
- 2
Chunking and embedding strategy
Choose chunk sizes per source type, decide on overlap and metadata, select the embedding model based on language and domain. Long-context models do not eliminate the need for retrieval; they reshape how aggressively we can chunk.
- 3
Hybrid retrieval and reranker build
Stand up the vector store and the keyword index, build the hybrid query layer, add a cross-encoder reranker for the top candidates. Pure vector search is rarely enough on real corpora.
- 4
Generation, attribution, and refusal
Wire the LLM call with retrieved context, structured-output enforcement, source attribution in the response, and a documented refusal path when evidence is weak. The refusal path is required, not optional.
- 5
Evaluation harness and production cutover
Build the evaluation set from real queries, score on answer accuracy, attribution correctness, and refusal calibration. Production cutover is gated behind a passing scorecard. CloudNSite continues to monitor, tune, and ship updates.
Related Guides
Explore
How to Switch from Manual Workflows to AI Agents
Switch from manual workflows to AI agents with a practical rollout plan. Identify first automations, expected ROI, timeline, and change management steps.
Explore
Alternatives to Generic Chatbots for Business Operations
See alternatives to generic chatbots for business operations. Compare scripted bots with AI agents that run workflows, connect systems, and take action.
Explore
Best AI Agents for Small Medical Practices
Compare the best AI agents for small medical practices with 1-10 providers. Learn costs, staffing impact, and HIPAA-ready setup without internal IT teams.
Frequently Asked Questions
What is the difference between RAG and fine-tuning?
RAG retrieves source documents at query time and grounds the model's response in them. Fine-tuning bakes patterns into model weights. For most enterprise knowledge use cases RAG is the right default because content changes constantly and you need source attribution. Fine-tuning is useful for style and behavior, not for facts that change.
Do we need a vector database for RAG?
You need a place to do similarity search. That can be a dedicated vector database (pgvector, Pinecone, Qdrant, Weaviate, Milvus), a search engine that supports vectors (Elasticsearch, OpenSearch), or a hybrid setup. The right answer depends on data volume, query mix, and existing infrastructure.
How does CloudNSite keep RAG from leaking sensitive documents?
Per-query authorization against the source-of-truth ACL, not the index. PII or PHI redaction before content reaches the model. Per-user retrieval filters baked into the query pipeline. Audit logs of every retrieval. We do not assume the index is a security boundary.
Should the LLM be private or can we use OpenAI or Anthropic APIs?
Both are options. Public APIs are fine when data classification allows it and the vendor offers a data processing agreement that matches your obligations. Private deployment is required for HIPAA, regulated financial workloads, defense, or any policy that prohibits prompt and response data leaving your boundary.
How long does an enterprise RAG implementation take?
A focused single-domain RAG (one knowledge base, one user group) typically ships in 4 to 6 weeks. Multi-source enterprise RAG with permissions, freshness pipelines, and evaluation harness usually runs 8 to 12 weeks. Regulated builds add compliance review time.
How does this work with long-context models like Claude or GPT?
Long context reduces some retrieval pressure but does not eliminate it. Cost, latency, recall on long inputs, and the need for source attribution all argue for retrieval. We use long context to pull more retrieved candidates, not to skip retrieval.
How do we measure if the RAG system is actually working?
We score on answer accuracy against a curated evaluation set, attribution correctness, refusal calibration, and end-user task completion. Drift detection runs on every deploy. We report the scorecard, not vanity metrics like query volume.
Who operates the RAG system after launch?
CloudNSite. We build the retrieval pipeline, embedding strategy, evaluation harness, and monitoring, then continue to tune, reindex, and ship updates. The team has access to dashboards and the evaluation scorecard, but operations stay with us.
Ready to Fix This Workflow?
Plan a RAG Implementation. Plan a custom build for this workflow or run the AI readiness check for a fast baseline.