Technical guide from CloudNSite engineering
LLM Evaluation Built for Production Systems, Not Demos
An LLM evaluation program decides whether a model change, prompt change, or retrieval change makes the system better or worse. CloudNSite builds the harness, curates the eval sets, wires LLM-as-judge where it earns its keep, and operates the program after launch. Real signal, not vibes.
System diagram
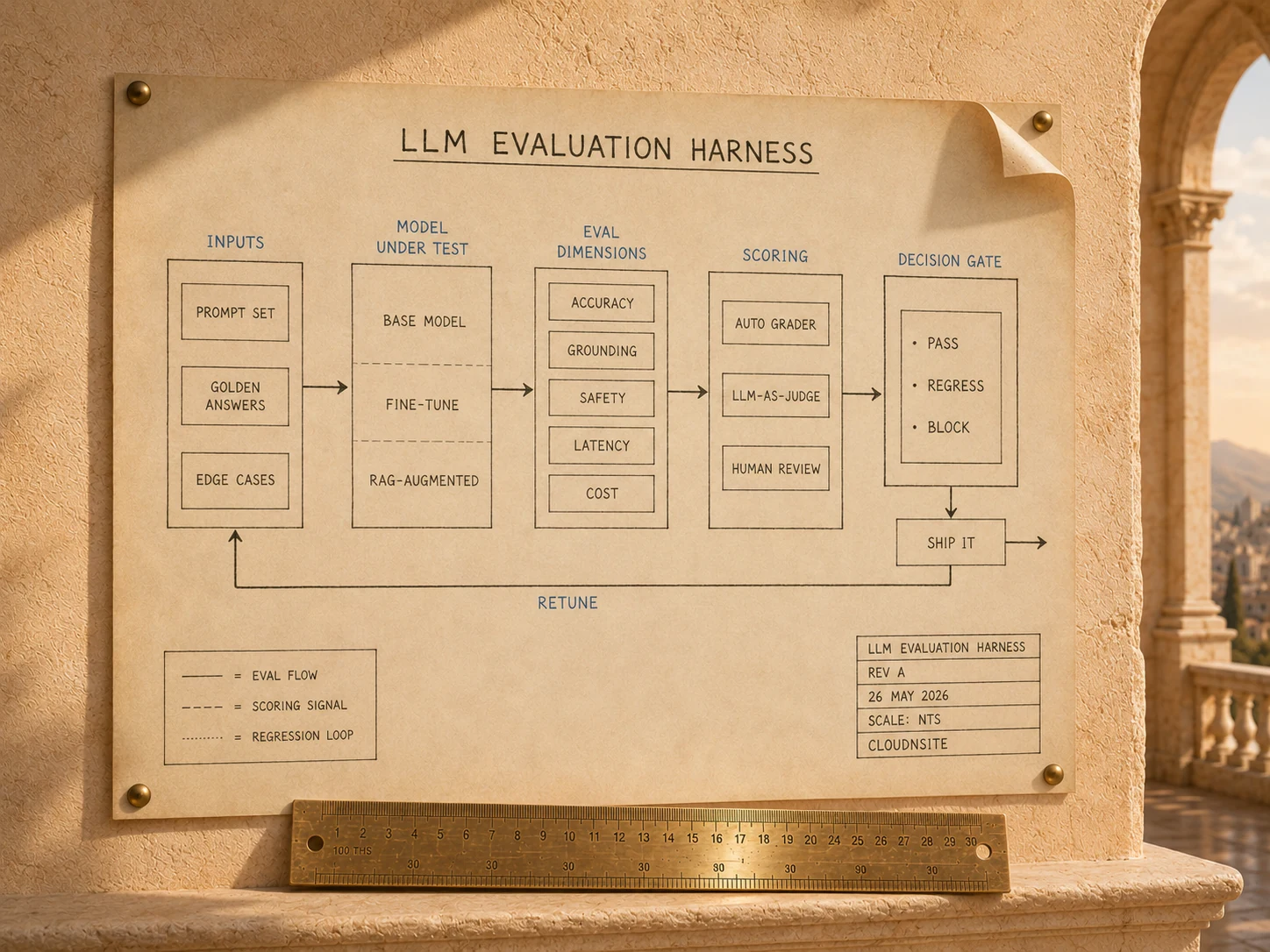
Direct answer
LLM evaluation is the practice of measuring whether an AI system answers correctly, refuses appropriately, and stays consistent under change. A production eval program has three layers: a curated regression suite that runs on every change, an adversarial red-team set that probes failure modes, and a production sampling loop that catches the cases nobody anticipated. Generic benchmarks (MMLU, HumanEval) almost never substitute for a domain-specific eval set.
Key definitions
- Eval set
- A curated collection of inputs paired with judged outputs or pass/fail criteria. The eval set is the contract: the system must satisfy it on every change. Good eval sets are domain-specific, version-controlled, and grow with production failures.
- LLM-as-judge
- A pattern where a model scores the output of another model against a rubric. Cheaper than human review and consistent across runs, but sensitive to prompt design and biased toward verbose answers if the rubric is not pinned. Useful when paired with periodic human calibration.
- Regression suite
- The subset of the eval set that must pass on every change. Treat regressions as production incidents. A failing regression blocks the deploy. Without this discipline, quality drifts silently as models, prompts, and retrieval evolve.
- Red team set
- Adversarial inputs designed to probe specific failure modes: prompt injection, sensitive content extraction, scope violations, hallucination, refusal failures. Expanded continuously based on production logs and threat intelligence.
- RAG eval
- Evaluation focused on retrieval-augmented generation: did retrieval surface the right chunks, did generation ground every claim, did citations resolve, did the system refuse correctly when the corpus had no answer. Different metrics than pure generation eval.
- Agent eval
- Evaluation focused on multi-step agents: did the agent pick the right tool, were tool arguments valid, did the workflow terminate, did the final state match the goal. Trajectory-level metrics matter more than single-turn quality.
Five layers of a production LLM evaluation program
An eval program that earns its keep has five layers. Skip one and the gap shows up in production. CloudNSite ships all five and instruments each layer so failures are attributable and fixable.
Curated eval sets
Domain-specific inputs with judged outputs, organized by capability (intent classification, grounding, refusal, tool selection, end-to-end workflow). Version-controlled. Grow from production failures and stakeholder review sessions.
Scoring harness
A repeatable runner that executes the eval set against any model, prompt, or retrieval configuration. Produces per-case results plus aggregate metrics. Outputs are stored so any deploy can be compared to any prior baseline.
LLM-as-judge with human calibration
A scoring model with a pinned rubric for outputs that are too expensive or too subjective to grade rule-based. Human reviewers calibrate the judge on a sampled set every cycle so judge drift does not mask system drift.
Production sampling and feedback loop
A small percentage of live traffic is reviewed by a human or a second model. Disagreements feed back into the eval set. This is how the harness learns about failure modes nobody anticipated at design time.
Reporting and gating
A dashboard showing pass rate per capability, drift over time, regression coverage, and the diff against the last baseline. Quality gates block deploys that regress. Reports go to engineering, product, and (in regulated environments) compliance.
When to use this
- You ship a model, prompt, or retrieval change and currently have no objective way to know whether quality improved or regressed.
- Your system has been in production long enough that user complaints are the primary quality signal.
- You operate in a regulated domain (healthcare, finance, legal) where audit evidence of AI quality testing is required.
- You are about to swap models or providers and need a defensible answer to 'is the new one better.'
- You are scaling a RAG or agent system and the failure modes are no longer obvious to engineering.
When not to use this
- The system is a throwaway prototype with one user. A few manual spot checks are cheaper than a harness.
- You have no concept of what 'correct' looks like for the task. Build the rubric first, then the harness.
- Generic benchmarks (MMLU, HumanEval, MT-Bench) are being used as a substitute for domain evaluation. Public benchmarks measure model capability, not your system's correctness.
How CloudNSite implements it
- 1
Curate the first eval set
Run a working session with engineering, product, and the domain experts to pull 100 to 300 representative inputs from production logs (or representative synthetic cases for new systems). Tag each by capability. Judge the outputs. Version it.
- 2
Build the scoring harness
A repeatable runner that executes the eval set against the current system configuration. Stores per-case results and aggregate metrics. Wires LLM-as-judge where rule-based scoring is too brittle. Outputs a comparable report against any prior baseline.
- 3
Wire the regression gate
Pick the subset of cases that must pass. Wire the gate into the deploy pipeline so a regression blocks the release. Document the override process for genuine intentional trade-offs.
- 4
Add the red team and production sampling layers
Curate the adversarial set (prompt injection, refusal failures, sensitive content extraction, scope violations). Stand up the production sampling loop with human review for the percentage of traffic that warrants it. Feed disagreements back into the eval set.
- 5
Operate, calibrate, and grow the program
Run the harness on every change. Recalibrate LLM-as-judge against human reviewers each cycle. Add cases from production failures within a week of detection. Report against the baseline. CloudNSite operates this loop alongside the engineering team.
Tools and standards we use
Custom harness in TypeScript or Python, run from CI
We build the harness to match the system architecture. Off-the-shelf eval frameworks (Promptfoo, DeepEval, Ragas, OpenAI Evals) are good starting points but rarely cover the full domain shape.
NIST AI RMF Measure function
The eval program is the operational expression of the Measure function. Documentation maps directly to MEASURE.1 through MEASURE.4 controls.
ISO/IEC 42001 testing and monitoring controls
Eval set version history, harness logs, and regression reports form the audit evidence for AIMS testing and performance monitoring requirements.
Faithfulness, context relevance, answer relevance metrics
We adapt the Ragas-style metric set to the domain corpus and pair with human review for the cases the metrics miss.
Trajectory-level metrics: tool selection accuracy, argument validity, workflow termination, end-state match
Single-turn quality misses the failure modes that kill agent systems. We grade the trajectory, not just the final message.
Curated dashboards plus human review queue
Percentage of live traffic flows to review. Reviewer disagreements become new eval cases within the same week.
From the field
RAG implementation evaluation harness
Every CloudNSite RAG build ships with an evaluation harness that scores faithfulness, context relevance, and refusal correctness on a domain-specific eval set. The harness runs on every model, prompt, and retrieval change. Regressions block the deploy.
Read the full case studyFrequently asked questions
Why are public LLM benchmarks not enough?
MMLU, HumanEval, MT-Bench, and similar benchmarks measure model capability on generic tasks. They tell you almost nothing about whether the model answers correctly on your domain, in your tone, against your corpus. Your eval set is the only reliable signal for your system.
How big should the eval set be?
100 to 300 cases is enough to start. Beyond 1000 cases, the cost of running the harness and judging outputs starts to matter. Grow the set by adding production failures, not by padding it with synthetic variations of cases you already cover.
Is LLM-as-judge reliable?
Reliable enough when the rubric is pinned, the judge model is held constant, and human reviewers recalibrate the judge against a sampled subset each cycle. Unreliable when used as a one-shot grader with no calibration. The judge model and rubric are part of the eval contract and must be versioned.
How does this fit into our existing CI pipeline?
The harness runs as a CI job on the branch. Regression gates block the merge. For deploys to production, a separate gate runs the full eval set including the adversarial subset. We wire both gates and document the override process for intentional trade-offs.
Who owns the eval set after launch?
CloudNSite operates the harness and curates the eval set alongside the engineering team. New production failures land in the set within a week of detection. The set is version-controlled in the same repo as the system.
How do you evaluate a multi-step agent?
Trajectory-level metrics: did the agent pick the right tool, were the tool arguments valid, did the workflow terminate, did the final state match the goal. Single-turn quality misses the failure modes that kill agents. We grade the trajectory, not just the final message.
Do you cover bias, fairness, and safety evaluation?
Yes, where the system context calls for it. For regulated or customer-facing deployments, the red team set includes fairness probes, refusal correctness across protected categories, and known prompt-injection patterns. The eval program contributes to NIST AI RMF MEASURE and Manage functions.
How does this relate to AI governance?
The eval program is the operational layer of an AI governance framework. NIST AI RMF MEASURE and ISO/IEC 42001 testing controls require the kind of evidence the harness produces. We design eval programs to satisfy both engineering needs and audit evidence requirements in one pass.